lazy.nvimのプラグインの保存先を知る方法
自分はNeovimのパッケージマネージャーにlazy.nvimを使用しています。 colorschemeであるeverforestの行番号のカラーをオーバーライドするために、colorschemeプラグインであるeverforestがどのように書かれてるか調べる必要がありました。 そのため、プラグインがどこに置かれてるか知る必要があったのでここにメモしておきます。
環境はMacOS X上ですが、Linuxでも同様かもしれません。(Windowsはわからない)
結論
結論から言うと保存先は
~/.local/share/nvim/lazy
のパス配下になります。
元々どこにプラグイン本体が置かれてるか分からなくて色々見てたんですが、lazy.nvimはそもそもどこにインストールされるのだろうと考えてそこから調べました。
lazy.nvimのREADMEを見てると、インストールスクリプトにこう書かれてました。
local lazypath = vim.fn.stdpath("data") .. "/lazy/lazy.nvim" if not vim.loop.fs_stat(lazypath) then vim.fn.system({ "git", "clone", "--filter=blob:none", "https://github.com/folke/lazy.nvim.git", "--branch=stable", -- latest stable release lazypath, }) end vim.opt.rtp:prepend(lazypath)
このlazypathが恐らくインストール先かなと思い
print(vim.fn.stdpath("data"))
を実行させると
~/.local/share/nvim
が出てきたのでここを ls で調べるとプラグイン保存先を見つけることができました。
余談
READMEにちゃんと保存先書かれてました(トホホ) https://github.com/folke/lazy.nvim#-uninstalling
data: `~/.local/share/nvim/lazy`
READMEはちゃんと読もう。
サラ金トラブル(生活レスキューガイドブック)という本を読んだ
部屋に積んであった大量の本の中からタイトルに惹かれて読んだ。
自分はお金の知識がなかったが、借金の怖さや周辺知識を初心者でも分かりやすく書かれており大変良い本だった。
実際の事例を元に豆知識等を紹介しており、大事なポイントは今後も覚えておきたい。
(出資法の軽い歴史みたいなのも書いてあって、制定当時は上限金利が109%!!まであってびっくらこいた)
以下要約
【序章】 お金は簡単には貸さない。 借金をしてはいけないと考えたり教育するのは良くない => 万が一借金を抱えた時に、「悪いこと」だと信じ込んで内緒で誰にも相談せず借金を積み重ねてしまう可能性がある。
借金をしっかり払う「真面目な」人は貸金業者からしたら上客。注意。
ハンコは安易に押さない。
【1章】 借金をする時は「書類」が最重要。 「受取証書」は業者が必ず発行しないといけないもの。 これは完済時まで必ず保持をしておかないと後悔する。
借金をしてる人の肩代わりはその人の為にならない。 心を鬼にして貸さない事が大事。
どうしても借りてしまう自分が怖ければ「貸付自粛依頼」というものがあるのでそれで調べる。
【2章】 利息制限法で借りた金額の大きさによって利息制限が変わる。 => 実際のサラ金はこれを無視してたりする。 「みなし弁済」という要件を満たせば可能らしい。 (グレーゾーンという)
ただ実際はこの要件を満たす事例はほとんどなく、上限を超えた金利は無効なことがほとんどらしい。
【3章】 家族の借金は支払い義務はない。 未成年の子供が勝手に行った契約は無効にできるらしい。
負債で首が回らなくなった場合、商事債権の失効は大体5年。(ただし様々な理由で時効を中断できる) => まずは法律相談センターにいくのが大事
任意整理とは債務者が払えなくなった時に収入から最低限の生活費を引いた残りを原資として負債を返していく方法。
弁護士に債務整理をお願いするときの注意点 ・嘘をつかない ・全て晒す事
自己破産は意外と破産者本人は死ぬわけでもないし大きなデメリットはない。
【4章】 内容証明=その手紙の内容が確かにあなたに配達されたということを郵便局が証明する効力の強い書類
取り立ての行き過ぎた行為は慰謝料を取れる可能性がある。
【5章】 公正証書=公証人が作成する書類。内容が裁判所の判決と同等の効力を持つ書類
これがあると業者が強制執行を実行する可能性がある。 本来債務者と業者双方の話を公証人は聞いて書類を作成する必要がある。 => 実際は債務者抜きで作ろうとして強制執行することが多い。
何も知らない債務者に白紙委任状と印鑑登録証明書を出させる。
つまり安易に白紙委任状と印鑑登録証明書を出さない事が大事。
【6章】 負債者を一見救うように見えて実際は悪質な業者ということがある。 買取屋 紹介屋 "整理屋"
特に整理屋は気をつける。弁護士事務所の看板を掲げてる事もあるが実際は名前を貸しているだけ。
良い弁護士の見分け方 ・債務整理に精通 ・債務整理方法や弁護料費用の説明をしっかりしてくれる ・交渉経過を教えてくれる
困ったら相談センターの弁護士に。
Rustの&strとStringについて整理したかった
はじめに
Rustを触っていて今までなぁなぁで&strとStringを使っており、少し調べて違いを整理したかったのでこの記事を書いてみました。
間違った事を書いている可能性もあるので参考にする際は十分にご注意ください。
では、&strとStringを知る上でRustのスライスという概念とメモリのスタック領域とヒープ領域の知識が必要なのでまずはそこから書いていきます。
スライスについて
Rustにはスライスという概念があります。
スライスとはコレクション内の一連の要素を参照したものです1
コレクションとはRustのデータ構造の一つで、複数の値を含むことのできる型です。ヒープに確保され、実行時に伸縮可能なのが特徴です。ベクタや文字列(String)やHashMapなどがコレクションに該当します。
スライスは2つのデータからできており、一つは開始地点のポインタ もう一つはそのスライスの長さ(length)です。これらはスタックに積まれます。2
例えば以下のようなコード
let message = String::from("Hello world"); //"world"が取り出される let world = &message[6..11];
があったとして、メモリモデルをイメージすると以下のようになります。

今回のスライス worldは先頭が'w'なのでwがあるポインタを指しています。
スタックとヒープ
次はヒープとスタックについてです。
メモリの領域にはヒープ領域とスタック領域という領域があります。他にもいくつか領域はありますが今回はヒープとスタックに絞ります。
ヒープ
ヒープはサイズが可変なデータを保持するためのメモリ領域です。ヒープにデータを置く際、プログラムはOSを訪ねてOSは十分なサイズの空のメモリ領域を見つけ出し、その領域を使用中としてその領域のポインタをプログラムに返します。ポインタはメモリ上のアドレスです。これらの一連の流れをアロケートすると言います。
ポインタ自体は固定サイズなので後述するスタックに積まれます。 ですからヒープのデータが必要になる際は、スタックにあるポインタを追う必要があります。
ヒープへのデータアクセスはスタックに比べ低速です。
スタックはデータ構造がシンプルなのに対し、ヒープはポインタを追う必要があるためです。3
スタック
スタックはLIFO(Last In, First Out)のデータ構造をした実行時に利用できるメモリ領域です。
LIFOとはLast In, First Outの略で、日本語で言うと後入れ先出しと言います。箱の中に本を縦に積み上げていったとしたら取り出す際は上から取り出す(つまり後から積み上げられたやつから取り出す)イメージです。
このデータ構造はとてもシンプルでデータを取りやすいため、スタックのデータアクセスは高速と言われています。
スタックにデータを積み上げる際、データは全て既知で固定なサイズでなければなりません。このこともスタックのデータアクセスが高速だと言われている理由の一つです。4
本当に触りの部分しか触れられていませんが、これらを頭に入れて&strとStringについて書いていきます。
&str
Rustには&str型とString型が用意されており、&strはプリミティブ型でStringは標準ライブラリが提供する型という大まかな違いがあります。
まずはこの&strについて書いていきます。
&strは先程書いた通りプリミティブ型に分類されます。
&strはスライスで一種で、文字列リテラルと呼ばれ、不変でありスタックに積まれます。
不変というのはread onlyでありリサイズが不可という事です。
文字列リテラルが不変なお陰でコンパイル時にどんなデータか判明するので、文字列は最終的なバイナリファイルに直接ハードコードされ非常に高速で効率的です。5
そして&strがRustではどういう風にメモリ管理されてるかイメージする上で大事なメモリモデルは以下の画像の通りです。

非常に簡潔かつ分かりやすかったので画像をYuki ToyodaさんのRustハンズオンのスライドから拝借しました。
画像の通り文字列リテラル&strはスタックにpreallocated read only memoryにある実データへのポインタとその長さlengthなどの文字列リテラルに関するデータを積みます。
&strは不変な文字列なのでCLIアプリの--helpで出力されるような実行時に動的に変わらないような文字列を保持したい時とかに使えそうです。
String
お次はString型です。
String型は端的に言うとヒープにメモリを確保し、コンパイル時にサイズが不明なテキストを保持できる型です。
公式の書き方で書くならば伸長可能、 可変、所有権のあるUTF-8エンコードされた文字列型です。6
Stringのメモリモデルは以下のとおりです。また拝借しました。

Stringは3つのパーツで構成されており、文字列の中身を保持するメモリ領域(ヒープ)へのポインタとその文字列の長さ(length)と確保したヒープの許容量(ヒープの再割り当てなしで格納できるUTF-8バイト長)でできています。これらはスタックに積まれます。7
Stringは伸縮可能なのでCLIアプリなどで標準入力を受けつける時に入力された文字列を保持する時などに使えそうです。なぜなら入力される文字列はコンパイル時には分からずユーザーによって変わる動的なものだからです。
最後に
Rustの文字列の扱いは今までJavaScriptぐらいしかやってこなかった自分にとっては難しくてとっつき辛かったです。
この記事で書いた事はRustの文字列周りのほんの上辺だけで本当はもっと複雑かもしれませんが、誰かの参考になれば幸いです。
最後まで読んでくださりありがとうございました。
-
https://doc.rust-jp.rs/book-ja/ch04-01-what-is-ownership.html#%E3%82%B9%E3%82%BF%E3%83%83%E3%82%AF%E3%81%A8%E3%83%92%E3%83%BC%E3%83%97↩
-
https://doc.rust-jp.rs/book-ja/ch04-01-what-is-ownership.html#%E3%82%B9%E3%82%BF%E3%83%83%E3%82%AF%E3%81%A8%E3%83%92%E3%83%BC%E3%83%97↩
-
https://doc.rust-jp.rs/book-ja/ch04-01-what-is-ownership.html#%E3%83%A1%E3%83%A2%E3%83%AA%E3%81%A8%E7%A2%BA%E4%BF%9D↩
-
https://doc.rust-jp.rs/book-ja/ch08-02-strings.html#%E6%96%87%E5%AD%97%E5%88%97%E3%81%A8%E3%81%AF↩
-
https://doc.rust-jp.rs/book-ja/ch04-01-what-is-ownership.html#%E3%83%A1%E3%83%A2%E3%83%AA%E3%81%A8%E7%A2%BA%E4%BF%9D↩

JavaScriptでArray.fill()を使用して二次元配列を作る時の注意点
この記事について
この記事では、JavaScriptでArray.fill()を使用して二次元配列を作る際の注意点について書いていきます。
自分がコードを書いた時に出会った問題を解決する時に知った事を残しておきます。
注意点について
簡単に言うとArray.fill()に配列(オブジェクト)を渡すと、そのオブジェクトへの参照がコピーされ配列に参照が格納されるという点です。
つまりオブジェクト(配列)の一箇所変更をしたら他のオブジェクト(配列)も釣られて変更されてしまう可能性があるということです。
例えばあなたが三目並べを作っていて、ボードを表す二次元配列を
const board = Array(3).fill(['', '', '']);
と作った場合、
[
['', '', ''],
['', '', ''],
['', '', '']
]
という二次元配列が出来上がります。
そしてバツ(✗)を表すプレイヤーが真ん中に入力したのでボードの状態を変更したとしましょう。
すると
[
['', '✗', ''],
['', '✗', ''],
['', '✗', '']
]
という状態になってしまいます。
これは3つの配列すべてが同じ参照(fill()に渡した[' ', ' ', ' '])を使用しているため、このようになります。
それぞれの配列データがfill()に渡された配列をコピーし独立しているわけではありません。
どういう問題に遭遇したか
Reactでなんか作りたいなと思ってリバーシを作ろうとしてる時に、ボードの初期化処理で上の挙動に悩まされたので今回は調べてみました。
同じではないですがこんな感じで
function createInitialBoard() { const rowLength = 8; const columnLength = 8; //まずは何も置かれてないボードを二次元配列で表現する const board = Array(columnLength).fill(Array(rowLength).fill('NONE')); //試しに適当な場所に石を置く board[3][3] = 'BLACK'; //以下省略 }
ボードを表現して初期石を配置するとReactは最終的に

とレンダリングしていました。そうですね、上にあるfillの仕様を知らなかったために全部変更されてますね。
解決策
const board = Array(3).fill().map(() => ['', '', '']);
とmap()を利用しましょう
fill()に引数を指定せず使用した場合、undefinedで埋めてくれます。その上でmap()が新たな配列を返すのを利用しそれぞれ独立した二次元配列を構築します。
最後まで読んでくれてありがとうございました。
出典
TypeScriptのライブラリの型定義を拡張する方法(with Discord.js)
最近Discord.jsでDiscordのBot(身内用)をTypeScriptで作っています。その中でDiscord.jsの型定義に追加したい型が出てきました。
import Discord from 'discord.js'; import { Command } from './commands/types/Command'; const client = new Discord.Client(); client.commands = new Discord.Collection<string, Command>();
こんな感じで後からDiscord.Clientオブジェクトにcommandsというプロパティを勝手に追加してるんですが、もちろんこんなものはdiscord.jsのDiscord.Clientの型定義に含まれていないので、自分で拡張してやる必要があります。
今回はその型を自分で拡張する方法を自分用にまとめておきます。
結論
独自の型定義ファイルを格納するためのディレクトリをsrcディレクトリ内に作成します。
mkdir src/types
独自の型定義ファイルを作成するため.d.tsファイルを作成。
touch src/types/client.d.ts
ファイルを開き、ファイル内で
import { Client, Collection } from 'discord.js'; import { Command } from './commands/types/Command'; //これはあんま今関係ない declare module 'discord.js' { interface Client { commands: Collection<string, Command>; } }
を記述。
あとは保存すれば自動で反映され
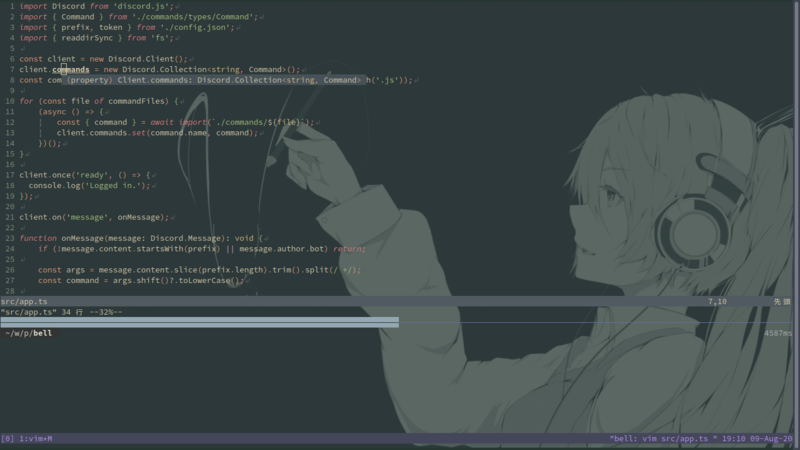
型がついてることがわかります。
解説
TypeScriptでは実装を定義しない宣言(型のみの宣言)をアンビエント宣言**と呼びます。
アンビエント宣言は .d.tsという拡張子を持ったファイルで宣言できます。
C++における .hファイルのようなものです。
今回はこのアンビエント宣言を利用し型を定義しました。
declare moduleとは
declare module "名前"
をアンビエント宣言内で記述することで "名前" で指定した型定義モジュールを指定することができます。
今回はdiscord.jsの型を弄りたかったので、declare module名にdiscord.jsを指定し、Clientの型を拡張しています。
interfaceのマージ
TypeScriptではinterfaceのマージが可能です。
例えば
interface Foo { bar: string; baz: string; }
というinterfaceが存在した場合
//前宣言したやつ interface Foo { bar: string; baz: string; } //新しい宣言 interface Foo { hoge: string; }
と新しくプロパティを追加してinterfaceを宣言すると
interface Foo { bar: string; baz: string; hoge: string; }
となり、マージされた形にすることができます。
今回はこれを利用し
interface Client { commands: Collection<string, Command>; }
としています。discord.jsにすでに定義されているClientの型にマージしています。
これらのようなマージをTypeScriptでは Declaration Mergingと言います。
お礼
最後まで読んでくださりありがとうございます。 わかりにくい文章かもしれませんが、お役に立てたら嬉しいです。
よく分からなかったのでCommonJSとTypeScriptのES Modulesinteropについて調べてみた
TypeScriptでExpressをちょびちょび弄ってて、Expressをimportする際esModuleinterop関連のエラーに引っかかったので、ついでによく分からなかったCommonJSやesModuleinteropフラグについて自分なりに調べてまとめておきます。
具体的にはtsconfig.jsonを作成しないで
import express from 'express';
としたら
node_modules/@types/express/index.d.ts:116:1 116 export = e; This module is declared with using 'export =', and can only be used with a default import when using the 'esModuleInterop' flag. // このモジュールは 'export =' で宣言されており、'esModuleInterop' フラグを使用している場合にのみデフォルトのインポートで使用することができます。
と出た時の話です。
端的に言うと、これを解決するにはメッセージ通りにtsconfig.jsonでesModuleInteropフラグを有効にする以外に
import express = require('express');
という記法で書いても解決できます。
TypeScriptでは、"export = "の記法でエクスポートされたものはTypeScript固有の
import module = require("module")
といった記法でimportする必要があるからです。
(参考: https://www.typescriptlang.org/docs/handbook/modules.html#export--and-import--require)
今回はその方法ではなく、もう一つのesModuleInteropフラグについてとCommonJSについて書いていきます。(CommonJSについて書くのはExpressがCommonJSモジュールで構成されてるからです)
CommonJSとは
一言で言うと、ブラウザ外におけるJavaScriptのモジュールシステムの仕様を策定することを目的としたプロジェクトです。
ブラウザ外というと、サーバーサイドにおけるNode.jsとかですね。
module.exports と exportsの違い
最初、Expressのコードを読んでいてCommonJSにおけるこの2つの違いがよく分かりませんでした。
大事なのはこの2つは根本的には同じということです。
どういう事かと言うと、内部ではこの2つは
exports = module.exports = {}
という風に同じ空のオブジェクトを指しています。
従って
exports.hoge = "hoge"; module.exports.fuga = "fuga";
とした場合、requireした側から見れば
{ hoge: 'hoge', fuga: 'fuga' }
という一つのオブジェクトとして認識されます。
Node.jsの公式ドキュメントでexportsがmodule.exportsのショートハンド版だと言われてるのはこのためです。
(出典: https://nodejs.org/api/modules.html#modules_exports_shortcut)
これらの使い分けとして
module.exportsはrequireして得られる値をそのままコンストラクタや関数として使いたい時に使いましょう。
例えば
//Game.js module.exports = class Game { constructor() {...} }
みたいなクラスをmodule.exportsしたとすると、
const Game = require('Game'); const game = new Game();
といったように、そのままnewして使えたりできます。
これがexportsでエクスポートしていたならば
//Game.js exports.Game = class Game {...}
const game = require('Game'); const game = new game.Game();
という書き方になり面倒です。
ただしES6では
const { Game } = require('Game'); const game = new Game();
といったオブジェクトの分割代入という記法も使えます。(参考: https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment#Object_destructuring)
対してexportsは、複数の関数やプロパティなどをエクスポートしたい時、requireした際得られる値をオブジェクトとして得たいときに使います。
//calc.js exports.add = (num1, num2) => {...} exports.sub = (num1, num2) => {...}
//main.js const calc = require('./calc'); console.log(calc); // { add: [Function], sub: [Function] } calc.add(1, 1); //2
みたいな感じです。
esModuleinteropとは
tsconfig.jsonのcompiler optionsには esModuleinteropというフラグがあります。
これはCommonJSとESモジュール間との相互運用を可能にするためのフラグです。
なぜこんなフラグが存在するのかと言うと、ES ModulesとCommonJSとの互換性に規約がないためです。
TypeScriptはESModulesに準拠していて、CommonJSモジュールを読み込むのにimport React from 'react'という構文をサポートするにはCommonJSモジュール側で exports.default というプロパティがエクスポートされている必要が有ります。 わざわざそんなものを書いてるものはレアなので、esModuleinteropがCommonJS側のモジュールに自動でdefaultを付け加えています。
実例を見てもらうと、
//server.ts import express from 'express'; const app = express();
というコードがあるとしてesModuleInteropを使いTypeScriptはこうコンパイルします。
//server.js "use strict"; var __importDefault = (this && this.__importDefault) || function (mod) { return (mod && mod.__esModule) ? mod : { "default": mod }; }; Object.defineProperty(exports, "__esModule", { value: true }); var express_1 = __importDefault(require("express")); var app = express_1.default();
2行目でrequireして得たオブジェクトにdefaultプロパティを追加しているのが伺えます。
esModuleInteropはコード生成時にこうしてCommonJSとES Moduleの相互運用性を担保しています。
つまりランタイムレベルで関係のあるCommonJSとES Modulesに関するフラグだという事です。
対して、TypeScriptのcompiler optionsには allowSyntheticDefaultImports というフラグが存在します。
このフラグはesModuleInteropフラグが有効であれば自動でオンとなっています。
allowSyntheticDefaultImportsとは
こちらもesModuleInteropフラグ同様、CommonJSとES Modulesとの相互運用を可能にするためフラグです。
じゃあ何が違うのかと言うと 実行時に影響せず、型チェックのみに影響する という点です。
どういう事かと言うとそのまま import React from 'react' のように書くとコンパイルエラーを吐きますが、allowSyntheticDefaultImportsを付けることでとりあえずコンパイルエラーは出ずコンパイルを通るようになります。
これをつけることで import React from 'react' という書き方をコンパイルエラーなしでとりあえずできます。
ですがあくまでコンパイル時のみに影響するものなので、コード生成には何の影響も及ぼさずコンパイルされたコードは動かないままでしょう。
esModuleInteropとallowSyntheticDefaultImportsの違いは端的に言うと 実行時に関係するかコンパイル時のみに関係するか です。
実験してみましょう。
//main.ts import express from 'express'; const app = express()
というソースコードを用意します。
npx tsc main.ts # tscはファイル名を指定してコンパイルするとtsconfigが読み込まれないので、allowSyntheticDefaultImportsはオフになってます
とするとコンパイルエラーを吐き出します。
ここで、allowSyntheticDefaultImportsを使うと
npx tsc --allowSyntheticDefaultImports true main.ts
問題なくコンパイルが通るはずです。
コンパイルされた main.js を実行してみましょう。
node main.js # TypeError: express_1.default is not a function
実行時エラーが出たはずです。
コード生成時に相互運用性を担保する仕組みが働いていないことがわかります。
最後に
ここまで読んでくれてありがとうございます!
自分でも文章がグチャグチャで分かりにくいだろうなというのを痛感しています。
Twitterもしているので、よかったら仲良くしてください!